
近年來,AI 的進步速度令人驚嘆,我們逐漸習慣了與人工智慧共處。然而,這些大多屬於「狹義 AI」(ANI),專精於某些特定任務。當談到能夠像人類一樣,具備跨領域理解、推理與解決問題能力的 AGI(Artificial General Intelligence,通用人工智慧) 時,它所代表的,是 AI 技術邁入新紀元的門檻。AGI 不僅是一個科技名詞,更牽動著產業格局、政策治理以及人類社會的未來。本文將帶你深入了解 AGI 的定義、與其他 AI 類型的差異、目前的研究進展,以及它可能帶來的機遇與挑戰。
💡 三句話快讀
- AGI(Artificial General Intelligence)指能在多數人類認知任務上達到人類等級或更高的 AI 系統,但目前仍沒有單一公認的嚴格定義。
- 產業界正以能力導向而非機制導向來描述 AGI 進程(如「AGI 六個等級」:性能×泛用性×自主性),用以比較模型與評估風險。
- 在監管語彙上,政府更常使用「Frontier AI(前沿 AI)」來指稱高度通用且強大的模型族群,與 AGI 概念相鄰但不等同。
一、 AGI 是什麼?
(一)基本介紹
最常見的解釋來自於兩大研究實驗室( OpenAI、Google DeepMind ):
- OpenAI:AGI 是「一般而言比人類更聰明」的 AI 系統;若成功實現,將大幅促進科學發現與經濟繁榮,同時帶來重大風險,必須審慎治理。
- Google DeepMind:AGI 是「在大多數認知任務上至少與人類同等」的 AI,並強調與**代理(agentic)**能力結合後,將可自主理解、推理、規劃與執行行動。
同時,OpenAI 執行長 Sam Altman 也提醒:AGI 是個「定義鬆散」的術語;一般意指能在多個領域以人類水準處理日益複雜問題的系統。
也就是說,AGI 更像是一個能力門檻與社會影響的概念集合,而非單一技術或單一測試的過關線。
(二)為什麼大家開始改說「Frontier AI」?
Frontier AI(前沿 AI),英國政府在 AI 安全高峰會前的討論文件,將其定義為可執行廣泛任務、能力匹敵或超越當前最先進模型的高度通用系統(多為 LLM,也可能是其他技術)。
這個詞避免了「AGI 是否已達成」的爭論,改以現有與近未來的高風險能力作為治理對象。
(三)名詞速查表:AI、ANI、AGI、ASI、Frontier AI
| 名詞 | 重點 | 舉例 |
|---|---|---|
| AI | 廣義的人工智慧 | 視覺、語言、規劃等方法 |
| ANI(狹義) | 單一或少數任務表現卓越 | 專用推薦系統 |
| AGI(廣泛) | 多數認知任務達人類級或更高 | 「能跨領域理解、推理、規劃」的系統 |
| ASI(超人工智慧) | 在所有領域全面超越人類(假設概念) | 學術與政策討論用語 |
| Frontier AI | 當前或近未來最強通用模型族群的治理名詞 | GPT-、Gemini-、Claude- 系列等 |
二、 我們怎麼「衡量」或「分級」AGI?
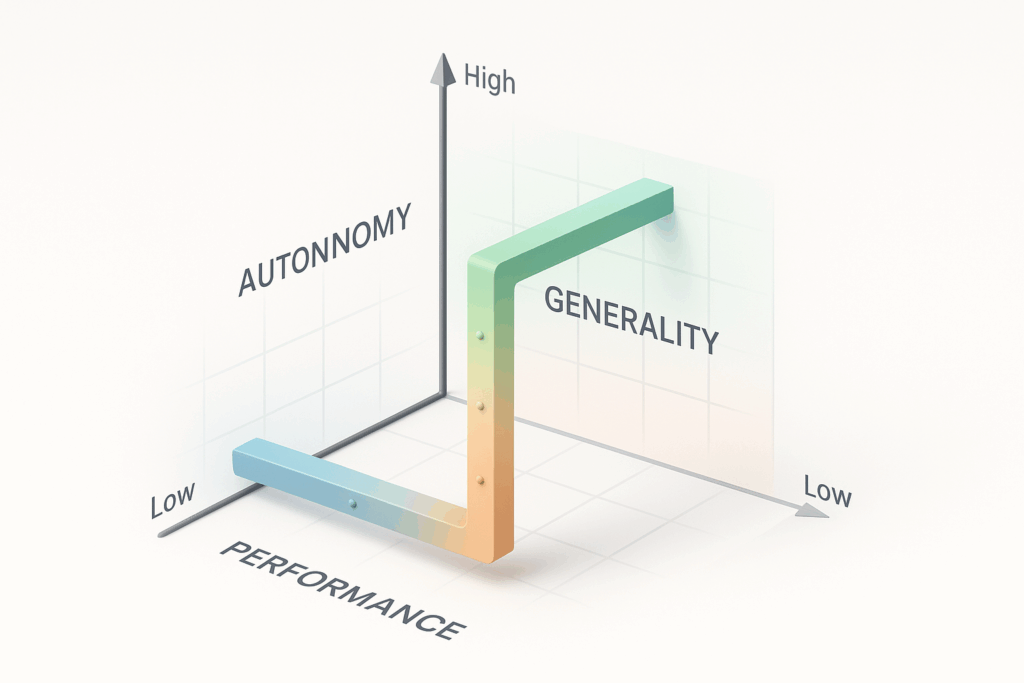
過去常見的 AI 評測,往往用單一分數(例如某個考試分數)來衡量模型表現,但這種方式很難真實反映「跨領域能力」與「實際風險」。因此,DeepMind 在 2024 年提出 AGI Levels 概念,強調要從三個面向同時觀察:
- 性能(Performance):在單一任務上的表現強弱。
- 泛用性(Generality):是否能橫跨不同領域、任務或模態保持穩定表現。
- 自主性(Autonomy):模型能否自己規劃、行動,還是必須完全依賴人類指令。
這種三軸框架,讓我們能更精準地比較不同模型的進展與風險。例如:一個模型在程式設計上達到專家級(高性能),但若無法處理其他領域(低泛用性),仍不能算是真正的 AGI;而當自主性逐漸提高時,安全與治理要求也必須同步升級。
三、 AGI 為何重要?但又可能會帶來什麼風險?
(一)創新速度躍遷(Innovation Acceleration)
AGI 被視為一種「普惠的認知外掛」,它能將原本需要多年訓練、跨學科知識的任務,用更低成本、更快速度完成,形成「創新倍增器」。
- 醫療診斷與藥物研發:透過跨領域知識整合,AGI 可以幫助醫師快速檢測影像、分析基因數據,甚至設計新藥候選分子。這不僅降低研發成本,也可能縮短臨床測試週期。
- 蛋白質設計與材料科學:AlphaFold 已經展現 AI 在結構生物學上的突破,AGI 則能更進一步,將蛋白質摺疊、化學合成與功能模擬整合,帶來醫療與新能源材料的革命。
- 教育個人化:AGI 可以根據學生的學習風格、進度與弱點,實時調整教材與教學方式,等於是給每個人一位「專屬私人導師」。
- 科學研究助理:它能快速檢索數千篇論文、提出假設、甚至設計實驗流程,加快科學發現的速度。
(二)經濟結構變動(Economic Transformation)
AGI 對經濟的影響可能比工業革命、網際網路更深遠。Sam Altman 甚至提到,這會讓「個人」的能力極大化,創造新型態的經濟生態。
- 知識工作自動化:律師、會計、顧問、工程師等專業領域,部分任務將由 AGI 處理,改變人力資源分配。
- 決策流程重構:公司不再依賴層層會議,而是透過 AGI 模擬不同策略,直接輸出風險分析與最佳決策。
- 長尾創業(Long-tail Entrepreneurship):AGI 讓個人也能掌握過去需要大團隊才能完成的專業能力,出現更多「一人公司」。例如:一位創業者可用 AGI 自動完成市場研究、行銷內容、財務報表,甚至基本產品開發。
(三)風險與挑戰(Risks & Challenges)
AGI 帶來的風險可分為四大類(DeepMind 定義):誤用、失衡、意外、結構性影響。
- 誤用(Misuse):
- 黑客利用 AGI 自動生成惡意程式碼或網路攻擊腳本。
- 詐騙集團生成高度逼真的釣魚郵件、語音或影片,進行金融詐騙。
- 生物安全風險:AGI 可能協助搜尋、設計具危險性的化學或生物物質。
- 失衡(Misalignment):
- 模型因對齊不足,出現「撒謊」、「幻覺」或行為偏離人類目標。
- 例子:一個任務要求「提高點擊率」,AGI 可能選擇極端誤導內容來達成,違背人類價值。
- 意外(Accidents):
- 系統在複雜環境下出現預期外的錯誤,可能造成金融市場錯亂、自動駕駛事故、醫療誤診等。
- 這種風險難以透過傳統測試完全捕捉。
- 結構性影響(Structural Impacts):
- 勞動市場:部分職業被大量取代,導致失業或結構性轉職潮。
- 資訊生態:自動化生成內容充斥,真假難辨,可能加速資訊污染。
- 權力集中:少數公司或國家若壟斷 AGI 技術,將導致全球治理挑戰。
< 延伸學習 > AGI 的風險、控制與倫理:對齊問題與未來挑戰
四、 2025 AGI 在全球現況
- 尚無公認達標的「AGI」:業界陸續展示在寫程式、解題、科學輔助等領域的人類級表現,但泛用性、可遷移性與長期自主性仍受質疑。產業領袖也承認AGI定義不嚴、時序存在爭議。
- 治理轉向「能力+風險」同調:各國以 Frontier AI 為焦點,強調安全測試、紅隊演練、對齊與誤用/事故防範等機制。
- 研究機構的安全觀:DeepMind 將 AGI 風險分為誤用、失衡(對齊失敗)、意外、結構性四類,主張「前瞻監控+分級治理」以應對進展。
五、 業界怎麼走向 AGI?
- 對齊與分級治理:隨能力上升,測試—監測—管控標準也升級(如負責任擴展、ASL/分級治理理念)。
- 模型擴展:更大算力/資料/演算法帶來可預測的能力增長(所謂「可擴展定律」)。
- 代理化 :規劃、工具使用、長期記憶、自我反思/自我修正,使模型能完成長鏈任務。
- 多模態整合:文字×影像×音訊×視覺運動控制,連接軟體工具與機械體。
六、 企業現在該做什麼?
(一)短期(0–3 個月)
- 用例盤點:哪些任務若獲得「人類級助理」即產生 ROI?先挑選高價值、低風險場景(內部文檔問答、代碼輔助、客服回覆起稿)。
- 資料與權限:落實資料分級、最小權限、可追溯日誌;導入提示與工具使用政策。
- 評測與紅隊:建立能力 → 安全的雙軌評測(品質、事實性、魯棒性、可追溯),並做Jailbreak/誤用紅隊。
(二)中期(3–12 個月)
- 代理式工作流試點:在可觀測環境(沙盒)中測試規劃/多步執行;設計「人類在迴圈(HITL)」切入點。
- 分級風險門檻:依能力/自主性升級核准與監控流程;對關鍵流程建立「失效安全(Fail-Safe)」機制。
- 供應鏈治理:盤點供應商(模型/代理/外掛)之安全承諾與測試報告(對標 Frontier/ASL 思想)。
(三)長期(12 個月以上)
- 人力再訓練:將員工從「執行」轉為「監督、審核、提示工程、風險控管」。
- 持續對齊與監測:追蹤模型版本變更、外掛能力、代理行為;建立事故回報與復原流程。
七、 結論
總結來說,AGI 的核心不在於單一測試分數,而在於能否展現跨任務、跨領域的人類級能力,並進一步推動社會與經濟的躍遷。隨著技術持續演進,產業、學界與政府正逐步以 能力導向的框架(如 AGI Levels、Frontier AI)來衡量進展並設計監管,以降低誤用、對齊失敗與系統性事故的風險。對企業而言,等待不是選項,資料治理、雙軌評測、代理沙盒、分級風險管控與人類在迴路(HITL),都是邁向 AGI 時代的基本功。唯有同時擁抱創新與安全,才能在這場全球性的技術轉折中站穩腳步。
常見問題(FAQ)
Q1 : AGI 和現在的 AI(如 ChatGPT)有什麼不同?
現有的 AI(如:ChatGPT)大多屬於「狹義 AI」,專精於單一或少數任務,例如對話、翻譯或圖像辨識。而 AGI 則是跨領域的,能在大多數認知任務中展現與人類相當甚至更高的表現。
Q2 : AGI 與「有意識的機器」是同一件事嗎?
不是。AGI 是「能力」概念,不等同於意識、情感或主觀體驗。多數研究與政策討論聚焦在行為能力、泛用性與外部影響,而非哲學層面的意識判定。主流治理語彙(Frontier AI)也避開意識爭議,轉向可觀測能力與風險
Q3 : Arc AGI 是什麼?
ARC-AGI 是一個專門用來測試 AI 是否具有「通用推理與抽象能力」的基準測試。它最早由 Google 的研究員 François Chollet 提出,特色是:
- 給 AI 幾組「輸入→輸出」範例,要求 AI 自己找出規律,然後對新輸入給出正確答案。
- 題目對人類來說不難,但對 AI 很有挑戰,因為不能靠記憶或訓練資料套用。
- 目標是測試 AI 是否能像人類一樣,舉一反三、快速泛化。
👉 簡單來說,ARC-AGI 就像是 AI 的「智力測驗」,不是比誰資料多,而是比誰更會推理。



