
隨著 AI 技術快速普及,OpenAI 提供的 API 成為許多開發者與企業的首選。但不同模型、不同用途的收費差異很大,如何理解價格結構,並做出最合適的選擇,將直接影響應用的成本效益。本文將帶你快速掌握 OpenAI API 的價格比較,並提供最佳化策略,幫助你用最低成本獲得最大效益。
一、Token 是什麼?
簡單來說,Token 是一個大語言模型在「處理文字」時的基本單位,就像是我們小學所學到的cm、m、km等單位。它不是單純以「字」或「詞」為單位,而是根據模型的 tokenizer(標記器)把輸入的文本拆解成若干片段。這些片段可能是一整個詞、詞的一部分、也可能是一個符號、標點、甚至空白字等。
< 延伸學習 > ChatGPT Token 是什麼?概念、價格、應用一次了解
二、 OpenAI API 計價方式
在理解各個模型 API 價格前,需要先搞懂 OpenAI 的計費方式,才能提前優化成本預算。
ChatGPT API 是採用 token 計費模式,每當你發送請求時,無論是輸入還是輸出,系統都會根據 token 的數量來計費。因此,若要有效控制成本,應該透過 精簡輸入內容 與 控制輸出長度 來減少 token 消耗。
而為了方便使用者了解他們可能的 Token 數為多少,OpenAI 也提供了 官方 Tokenizer 工具 來幫助估算 token 使用量:
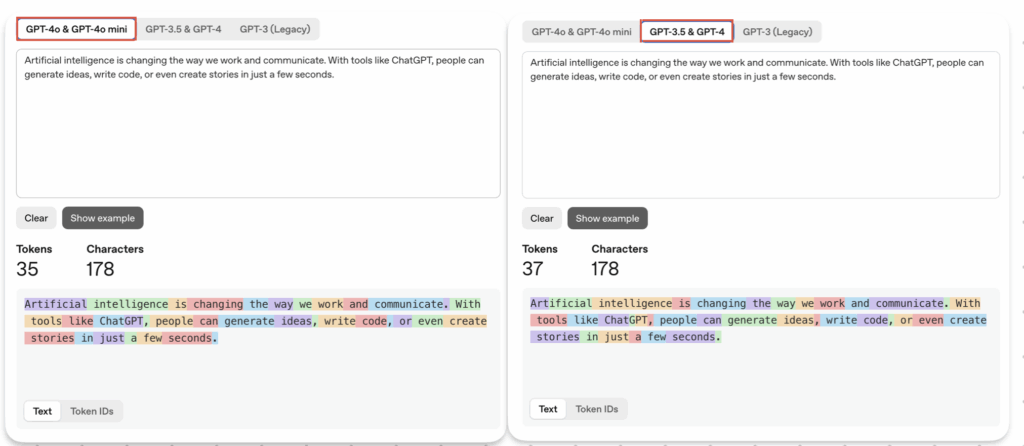
(一)英文文本
以英文來說,通常「100 個 token ≈ 75 個英文單字」,且在不同模型下所產出的Token 數也不盡相同。
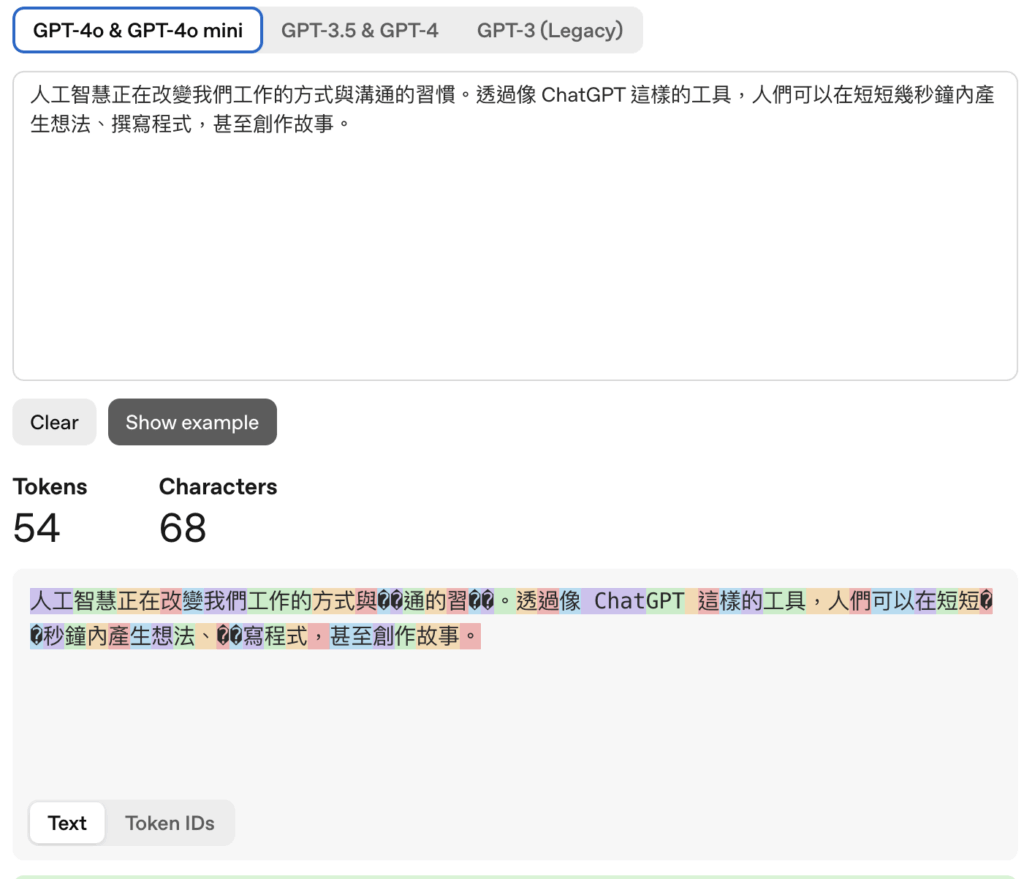
(二)中文文本
以中文來說,一個中文字大概就是一個Token ,且一定會比英文文本所耗的Token 數來的多。
三、 2025年,OpenAI 的熱門模型 API 價格一覽
學完了 OpenAI 是如何對 API 進行收費後,現在可以開始了解他們對於每個 API 的收費價格各是如何的。
(一)熱門模型一覽
| 模型名稱 | Input 單價 (USD / 1M tokens) | Output 單價 (USD / 1M tokens) | Cached Input 備註 |
|---|---|---|---|
| GPT-5 | $1.25 | $10 | cached $0.125 |
| GPT-5 mini | $0.25 | $2.0 | cached $0.025 |
| GPT-5 nano | $0.05 | $0.4 | cached $0.005 |
| GPT-4.1 | $2.0 | $8.0 | cached $0.5 |
| GPT-4.1 mini | $0.4 | $1.6 | cached $0.1 |
| GPT-4.1 nano | $0.1 | $0.4 | cached $0.025 |
| o4-mini(推理強化) | $1.1 | $4.4 | cached $0.275 |
| GPT-4o mini | $0.15 | $0.6 | cached $0.075 |
| GPT-image-1(生成圖像) | $10 | $40.00 | $2.5 |
(二)API 名詞小教室 : Input / Output / Cached Input 是什麼?
1. Input tokens(輸入)
你送進模型處理的內容(如系統提示、使用者訊息、工具回傳的文字)。費用依「輸入 token 數 × 該模型的輸入單價」計算。
2. Output tokens(輸出)
模型回覆產生的內容。費用依「輸出 token 數 × 該模型的輸出單價」計算。
3. Cached input tokens(快取輸入)
在多輪對話或長上下文中,重複且未改動的那一段輸入可被系統快取,以遠低於一般輸入的單價計費(多數模型約為一般輸入的 1/10)。
四、價格比較亮點
- 能力越強 → 單價越高:GPT-5、GPT-4.1 在 reasoning 與長文本上最強,但價格也最高。
- mini / nano 高性價比:適合摘要、分類、一般問答等需求。
- Cached input 節省顯著:對於上下文重複的應用(聊天機器人、知識庫),快取能大幅降成本。
- 用途差異明顯:圖像生成、即時處理 (Realtime) 成本高於純文字任務。
- 價格持續下探:OpenAI 不斷推出更便宜的小模型,反映出硬體進步與市場競爭。
五、實際應用成本估算
假設使用 GPT-5 mini:
- Input:2000 tokens → 2000 / 1,000,000 × $0.25 ≈ $0.0005
- Output:1000 tokens → 1000 / 1,000,000 × $2.00 ≈ $0.002
➡ 每次請求成本約 $0.0025
若每月 10 萬次請求,成本約 $250 美元。
六、如何進行成本控制,提供給你 4 種建議
想要降低成本,不僅是要選擇便宜模型,還需要最佳化使用方式,也就是找到適合你的模型:
(一)精簡 Prompt
- 刪掉贅詞:避免「請你幫我」這種多餘開頭,直接下指令。
- 避免重複:不要把相同的資訊複製貼上多次。
- 使用標題/項目符號:讓模型更快抓到重點,也減少句子冗長。
(二)善用上下文管理
- 摘要歷史對話:不要把整段長對話每次都塞進 prompt,改成人工或程式自動做摘要。
- 引用文件要節選:丟完整文件會爆 token,應先用檢索(如 RAG)只取相關片段。
- 系統訊息簡潔:System prompt 越長,成本越高,建議精煉成最小必要指令。
(三)選擇合適的模型與格式
- 選模型:若任務不需要 GPT-5,改用 GPT-4.1 mini 或 GPT-4.1 nano,可以省 token + 成本。
- 輸出格式精簡:若只要 JSON,避免要求模型生成過多文字解釋
(四)控制輸出長度
- 設定
max_tokens,限制模型輸出的 token 數。 - 若只要短答案,提示詞可以加上:「回答不超過 100 字」或「簡答即可」
七、結論
對企業或開發者來說,核心策略是 「依需求匹配模型」,並透過 批次處理、非同步任務、快取機制 等方式進行優化。唯有在功能與成本之間找到平衡,才能讓 AI 應用既強大又划算。這不僅意味著在不同場景選擇合適的模型,也需要持續追蹤 API 的用量與效能,建立透明的成本監控機制。長遠來看,能夠有效結合 模型選型 + 成本管理 + 應用優化 的團隊,才是真正能在 AI 時代中持續擴張、同時保持競爭力的贏家。



